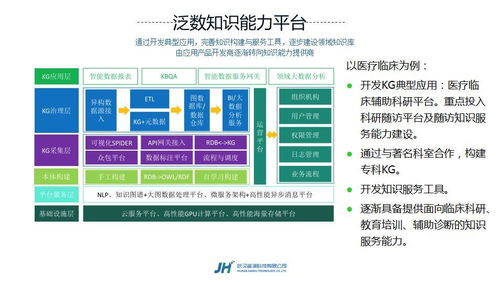
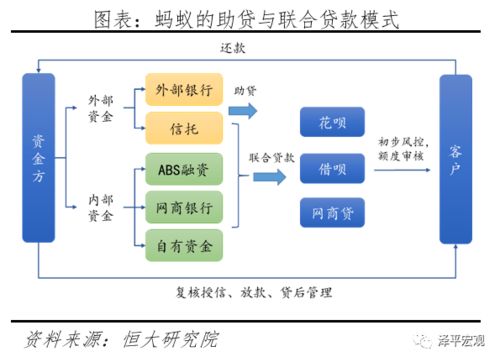
在當今的人工智能浪潮中,許多開發(fā)者過度關注算法和模型的精進,卻忽視了將深度學習技術真正轉(zhuǎn)化為可用的產(chǎn)品。本文旨在為技術團隊提供一份產(chǎn)品級深度學習開發(fā)的實用指南,幫助大家在互聯(lián)網(wǎng)技術開發(fā)中實現(xiàn)從理論到實踐的跨越。
一、需求分析與問題定義
產(chǎn)品級深度學習開發(fā)的第一步是明確業(yè)務需求。與純研究不同,產(chǎn)品開發(fā)需要回答:這個模型要解決什么問題?用戶場景是什么?性能指標如何定義?例如,在電商推薦系統(tǒng)中,我們不僅要關注準確率,還要考慮響應時間、可擴展性和用戶體驗。
二、數(shù)據(jù)工程與治理
數(shù)據(jù)是深度學習的基石。產(chǎn)品級開發(fā)需要建立完整的數(shù)據(jù)流水線:
- 數(shù)據(jù)收集與標注:確保數(shù)據(jù)的代表性、質(zhì)量和合規(guī)性
- 特征工程:構建有效的特征體系,考慮特征的可維護性和實時性
- 數(shù)據(jù)版本控制:跟蹤數(shù)據(jù)變更,保證實驗可復現(xiàn)
三、模型開發(fā)與迭代
在產(chǎn)品環(huán)境中,模型開發(fā)需要平衡多個維度:
- 性能與效率:在保證精度的同時控制計算和存儲成本
- 可解釋性:關鍵業(yè)務場景需要模型決策的可解釋性
- A/B測試:建立科學的實驗體系驗證模型效果
四、工程化與部署
將模型轉(zhuǎn)化為服務是整個流程的關鍵:
- 服務化架構:采用微服務設計,實現(xiàn)模型的高可用和彈性伸縮
- 監(jiān)控告警:建立完善的監(jiān)控體系,跟蹤模型性能衰退和數(shù)據(jù)分布變化
- 持續(xù)集成:自動化模型訓練、測試和部署流程
五、運維與優(yōu)化
產(chǎn)品上線后的工作同樣重要:
- 性能優(yōu)化:持續(xù)優(yōu)化推理速度和服務穩(wěn)定性
- 反饋循環(huán):建立用戶反饋機制,驅(qū)動產(chǎn)品迭代
- 成本控制:監(jiān)控資源使用,優(yōu)化硬件配置
六、團隊協(xié)作與流程
成功的深度學習產(chǎn)品需要跨職能協(xié)作:
- 數(shù)據(jù)科學家、工程師和產(chǎn)品經(jīng)理的緊密配合
- 建立標準化的開發(fā)流程和文檔規(guī)范
- 技術債務管理,保持代碼和模型的可持續(xù)性
產(chǎn)品級深度學習開發(fā)是一個系統(tǒng)工程,需要技術團隊在算法能力之外,建立起完整的產(chǎn)品思維和工程能力。只有將深度學習技術與產(chǎn)品需求、用戶體驗和商業(yè)價值緊密結合,才能在激烈的市場競爭中脫穎而出。記住,最好的模型不是最復雜的模型,而是最能解決用戶問題的模型。